在数字经济时代,企业征信作为金融基础设施的关键组成部分,其准确性与效率直接影响信贷决策、风险防控与市场秩序。沥金所作为一家专注于金融科技服务的机构,其企业数据征信模型的建设研究,不仅是自身业务发展的核心驱动力,更是对行业智能化、精准化转型的有益探索。本文旨在系统剖析沥金所在企业数据征信模型建设方面的研究路径、核心要素与业务价值。
一、 建设背景与业务需求
传统的企业征信模式往往依赖有限的财务数据、历史信贷记录与人工核查,存在信息滞后、维度单一、覆盖不全等问题。随着大数据、人工智能等技术的成熟,以及企业多维度数据(如经营流水、税务、司法、舆情、供应链、物联网等)的可获取性增强,构建更全面、动态、智能的企业征信模型成为可能。沥金所的企业征信业务面临客户对风险精准定价、快速审批响应以及覆盖长尾中小微企业的迫切需求,这直接推动了其数据征信模型的系统性研究与建设。
二、 模型建设的核心研究框架
沥金所的企业数据征信模型建设研究,主要围绕以下四大支柱展开:
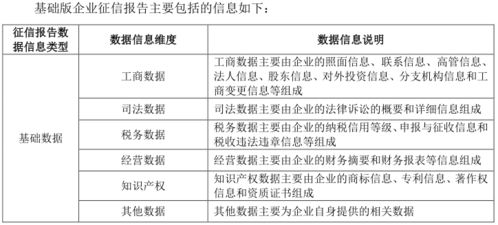
- 多维数据融合与治理:研究重点在于如何合法合规地整合内外部多元数据源。包括:
- 传统金融数据:信贷历史、担保信息等。
- 企业经营数据:对公账户流水、纳税信息、社保缴纳、水电消耗等。
- 公共与替代数据:司法诉讼、行政处罚、知识产权、招投标信息、媒体舆情等。
- 产业链与关联数据:供应链上下游交易稳定性、关联企业风险传导等。
研究涵盖数据清洗、标准化、关联关系挖掘以及持续的数据质量监控体系。
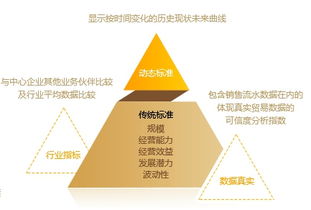
- 特征工程与指标体系建设:这是模型效能的基石。研究不仅从原始数据中提炼出成百上千个基础特征,更侧重于构建具有强预测能力的衍生指标与复合指标。例如,结合流水数据计算出的“经营稳定性指数”、“现金流健康度评分”,结合舆情与司法数据构建的“声誉风险指数”,以及反映企业成长性的“创新能力指标”等,形成一套立体化的企业信用画像指标体系。
- 智能算法模型构建与优化:研究综合运用机器学习与深度学习算法。初期可能采用逻辑回归、决策树、随机森林等可解释性较强的模型进行基础评分;进而引入梯度提升树(如XGBoost, LightGBM)处理复杂非线性关系;对于时序数据与复杂关系网络,探索使用LSTM等时序模型和图神经网络。研究核心在于模型的迭代优化、集成策略以及防止过拟合,确保模型在不同行业、不同规模企业间的泛化能力与稳定性。
- 模型应用与业务闭环:模型的价值最终体现在业务场景中。研究将模型输出(如信用评分、风险等级、违约概率)无缝嵌入信贷审批、贷后监控、客户关系管理等全流程。建立模型效果监控与反馈机制,利用真实的业务表现(如是否违约、额度使用情况)持续反哺模型,形成“数据输入-模型计算-业务决策-结果反馈”的闭环优化体系。
三、 对征信业务的价值赋能
通过上述研究与实践,沥金所的企业数据征信模型为其征信业务带来了显著提升:
- 提升风险识别精度:模型能够更早、更准地发现潜在风险信号,如经营状况的早期恶化、关联风险传染等,将风险防控从“事后应对”转向“事前预警”。
- 扩大服务覆盖范围:对于缺乏传统抵押物和完整财报的中小微企业,模型能通过替代数据有效评估其信用状况,破解“信息不对称”难题,助力普惠金融。
- 优化业务流程与体验:自动化、智能化的信用评估大幅缩短了审批时间,降低了人工成本,提升了客户体验与业务效率。
- 开发创新征信产品:基于模型的深度分析能力,可以衍生出行业风险报告、供应链金融风控方案、企业健康诊断等增值服务,拓展业务边界。
四、 面临的挑战与未来展望
研究与实践过程中,沥金所也面临着数据安全与隐私合规、数据孤岛与获取成本、模型可解释性与公平性、以及宏观经济周期对模型稳定性的冲击等挑战。其研究可能进一步向以下方向深化:探索联邦学习等隐私计算技术在合规数据融合中的应用;加强动态、实时数据的处理能力,构建“活体”征信模型;深化行业细分模型的开发,提升垂直领域的精准度;并推动与行业协会、政府部门的数据生态合作,共建更健康的企业信用体系。
结论
沥金所对企业数据征信模型的建设研究,是一项融合了数据科学、金融理论与业务实践的综合性工程。它不仅是技术能力的体现,更是对征信业务本质——即如何更全面、客观、动态地评估企业信用——的持续追问与创新解答。通过构建智能化、多维度的征信模型,沥金所有力地推动了自身企业征信业务向更精准、更高效、更包容的方向演进,也为整个金融科技领域的风险管理工作提供了有价值的参考范式。